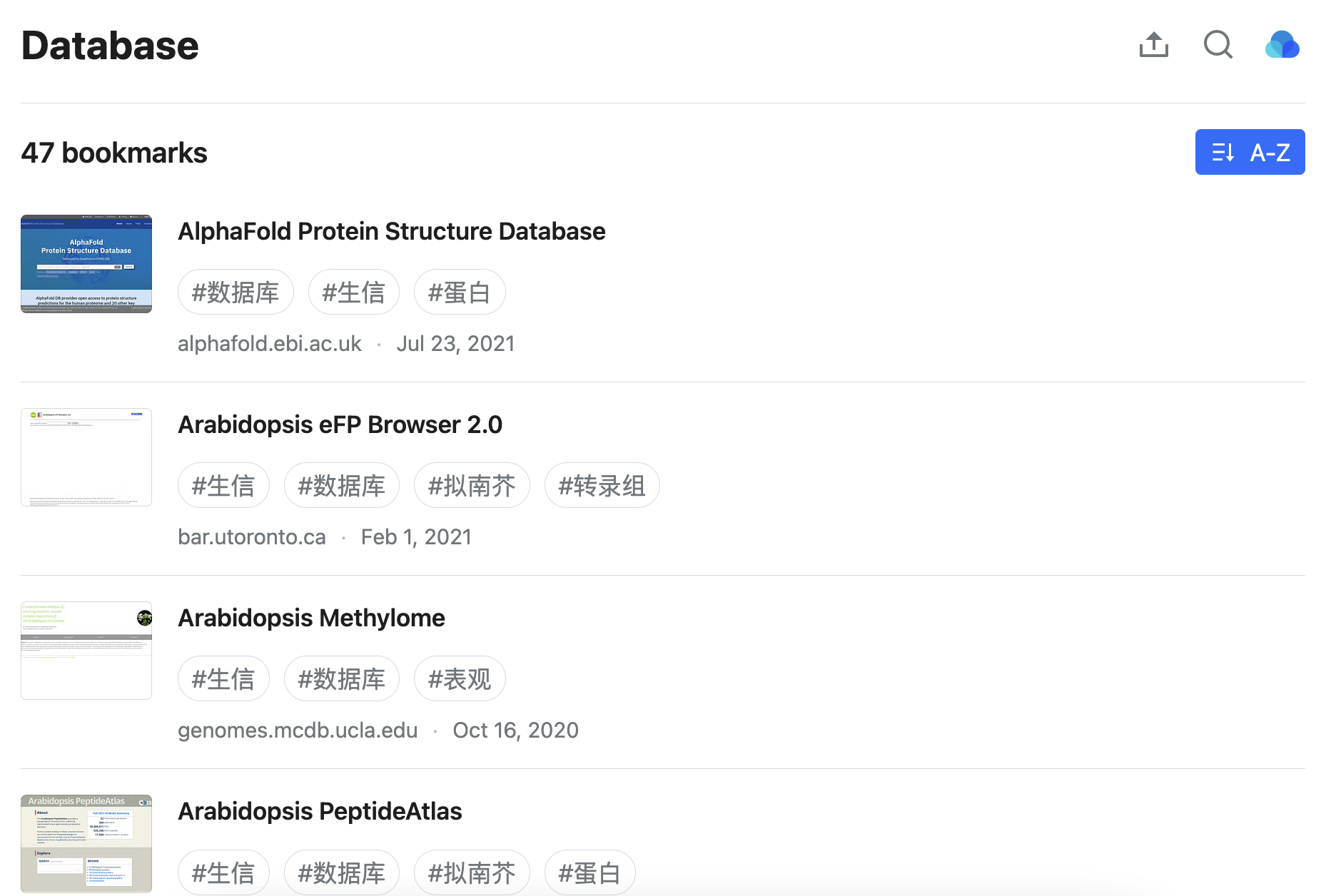
What
这是我日常会用到,所以整理出来的主要与植物学、基因组学有关的在线数据库集合。
链接在此:database
How-to
我利用了「#标签」的形式对链接进行分类,因此在检索的时候,可以直接点击下面的标签进行选择,也可以在搜索框中以「#标签名」的形式输入一个或多个标签进行筛选,多个标签之间使用空格隔开。
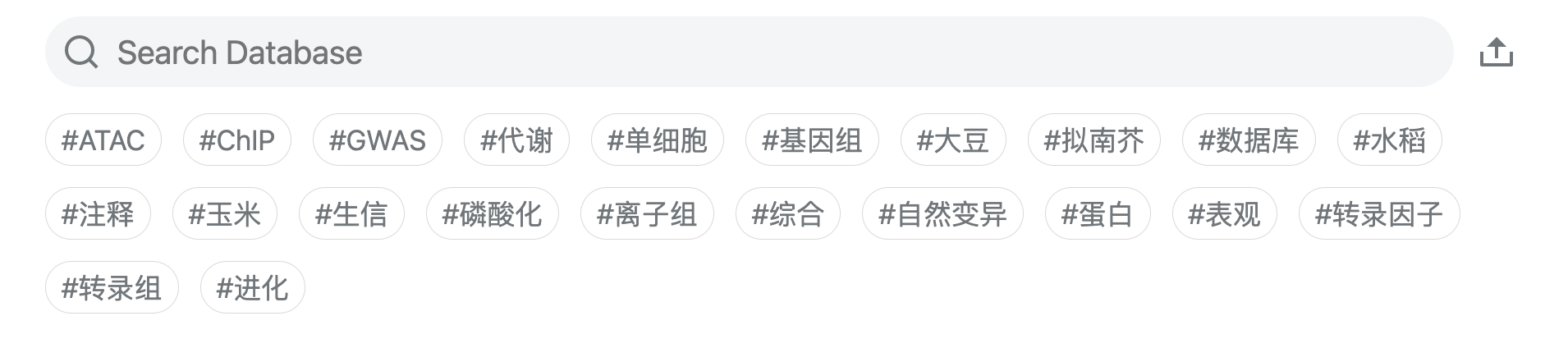
举个例子,假如想寻找和拟南芥蛋白有关的数据库,则可以在下面的标签中依次点击「#拟南芥」和「#蛋白」,也可以直接在搜索框中输入这两个标签。
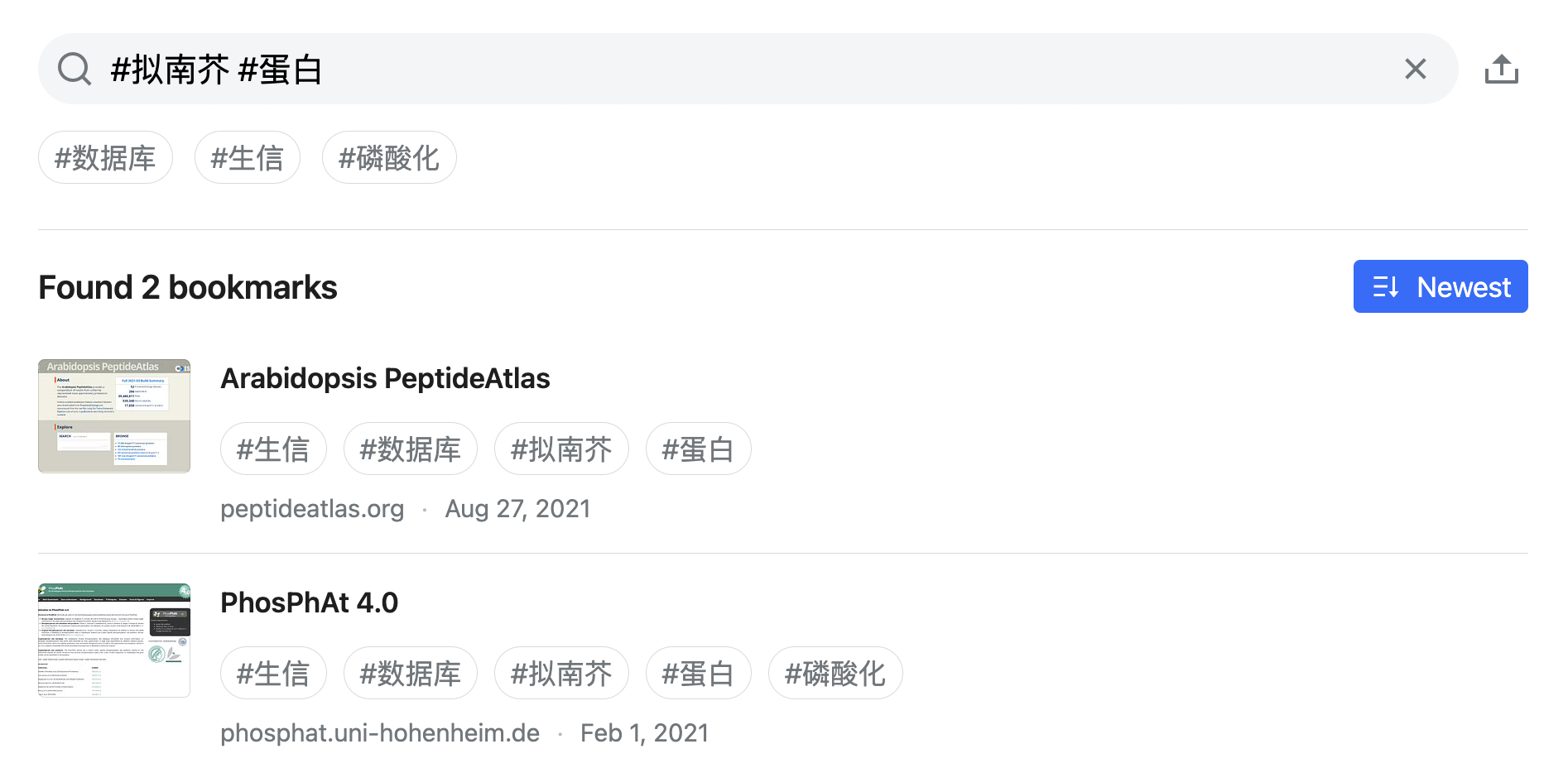
补充说明:
- 如果这个数据库只包含一个物种的数据,我会给它打上「#物种名」的标签,但如果它同时带有多物种内容,比如 NCBI 或是 Ensembl plants,我就不会给它打物种名的标签。
- 有些数据库我也没有想好怎样用最简短的标签进行概括,所以标签描述不一定完备,也欢迎提修改意见。
Why and why
为什么要做这个
知识共享也好,流动着的知识才是好知识也好,可能就是我觉得有意思吧。
为什么不用文件夹
文件夹组成的是一种树状结构,然而每个数据库的属性并不是整齐的树状。比如一个数据库,即可以带有「拟南芥」的属性,表明它主要是一个拟南芥的数据库,同时它还可能带有一个「蛋白」的属性,表明其是蛋白质结构、或是蛋白修饰的数据库,因此这样的数据库并不能单一地根据物种或是数据类型进行分类。
为什么使用 Raindrop.io
我使用了书签管理服务 Raindrop,直接对其中一个文件夹进行共享,因为一方面发现它很方便,不论是检索还是发布;另一方面,我也想过用 Notion 或是飞书的在线文档形式,可能会更稳定一点,但是我懒,不想再一条条输一遍了,也许之后发布方式会改吧。
后续计划
如何更新
欢迎提意见和建议,包括如何改进标签,更准确地描述数据库;有哪些新的数据库值得加入进来,Et cetera。可以留言或直接与我联系。